
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- software
- 커널 프로그래밍
- storage system
- performance
- Operating System
- Git
- linux
- Cache
- Machine Learning
- hardware
- FTL
- ssd
- 키워드
- 시스템 프로그래밍
- deep learning
- 포트 번호 변경
- core dumped
- 시스템 소프트웨어
- overflow
- USENIX
- Samsung
- memory
- Intel
- github
- rocksdb
- framework
- Flash Memory
- kernel
- Today
- Total
Happy to visit my research note ^^
(논문 세미나)Vigil-KV: Hardware-Software Co-Design to IntegrateStrong Latency Determinism into Log-StructuredMerge Key-Value Stores 본문
(논문 세미나)Vigil-KV: Hardware-Software Co-Design to IntegrateStrong Latency Determinism into Log-StructuredMerge Key-Value Stores
Liam Lim 2023. 3. 17. 12:08
Miryeong Kwon1 , Seungjun Lee1 , Hyunkyu Choi1 , Jooyoung Hwang2 , Myoungsoo Jung1 Computer Architecture and Memory Systems Laboratory, Korea Advanced Institute of Science and Technology (KAIST)1 , Samsung2
USENIX Association
2022 USENIX Annual Technical Conference
1. background
Log-structured merge key value store (LSM KV store)
대량의 데이터를 처리하기 위한 저장소 엔진 중 하나이다. LSM KVs는 기본적으로 디스크의 내부 상태를 유지하며, 새로운 데이터는 메모리에 쓰여진다. 메모리에 데이터가 충분히 쌓이면, 해당 데이터는 디스크에 쓰여진다.
이 때, 데이터는 디스크에 (+참고1)sequential하게 쓰여진다. 이를 장점으로 활용하기 위해 LSM KVs는 데이터가 디스크에 쓰여진 순서대로 저장되는 log file을 사용한다. 이 log file에는 새로운 데이터가 추가될 때마다 쓰여진다.
LSM KVs에서는 새로운 데이터가 메모리에 쌓이는 동안 디스크에서는 background 작업이 진행된다. 이 background 작업에서는 log file을 병합해서 더 작은 파일로 만든다. 이렇게 만들어진 파일들은 서로 다른 크기를 가지고, (+참고2)순차적으로 쓰여진 파일과 비교해서 읽기 성능이 높아진다.
이러한 LSM KVs는 데이터 처리 속도가 빠르고, 대용량 데이터 처리에 적합하다. 대규모 데이터를 처리하는데 매우 효율적이며, 데이터베이스나 (+참고3)분산 시스템에서 자주 사용된다. 하지만 데이터를 삭제할 때, log file에서 지워진 것으로 처리하지 않으면 저장 공간이 낭비될 수 있으며, 파일 병합이 늦어지면 일부 데이터에 대한 응답 시간이 지연될 수 있다.
LSM KVs는 persistence와 effectiveness를 위해 규칙적으로 compaction 및 flushing과 같은 내부 작업을 수행한다. compaction은 LSM tree의 하위에서 상위로 데이터를 병합하고, flush는 in-memory buffer를 기록하고 버퍼된 데이터를 지속시키기 위해 기본 스토리지에 기록한다. 이러한 내부 작업의 write operation은 long latency를 가지고 있고 종종 모든 들어오는 요청을 막기 때문에, 본 논문의 이전에는 내부 작업의 additional write operation을 reschedule하고 future idle times에 서비스하는 것을 권장한다. 이러한 LSM KVs는 내부 작업에 의해 부과되는 latency inconsistency (지연 시간 불일치)를 어느 정도 줄일 수 있지만, 저자들은 이것이 read service를 악화시키고 (+참고5) memory footprints를 크게 증가시키는 심각한 부작용을 유발하는 것을 관찰하였다고 한다.

Figure 1a는 RocksDB의 주요 데이터 구조와 해당 연산을 설명한다. RocksDB는 volatile memory와 block storage에 최적화된 두 개의 separate structures로 구성된 LSM tree에 모든 정보를 유지한다. MemTable은 unsorted(정렬되지 않은) 방식으로 데이터 상태가 persistent(불변의)하게 바뀌기 전에 data를 보관하는 in-memory data structure이다. memtable은 user/client가 memory에서 request를 처리해서 (storage에서 처리하는 것 보다) 빠르게 업데이트할 수 있도록 해준다. storage data structure는 key-value pairs를 관리하고 이는 Sorted String Table Files(SSTFiles)의 immutable한 형태로 관리된다. SSTFiles는 hierarchical level에서 유지되며, 각 Level은 L0 (level 0), L1 (level 1) , ….. , LK(level K)로 표시된다.
Client operations.
RocksDB는 Put (writes), Get (reads), Delete, and Scan과 같은 다양한 query services를 지원한다. 그러나 대부분의 queries는 Put과 Get이므로 이 연구는 두 작업에 중점을 둔다. RocksDB에서 Users' Put request는 Memtable이 mutable하다면(= KV pairs를 추가할 수 있는 공간이 있다면) KV pair로 Memtable에 삽입된다. RocksDB는 기본적으로 두 개의 Memtable을 유지하며, 각각 64MB 크기를 가지고 log file의 크기와 같다. LSM KV의 internal tasks(즉, flush와 compaction)에 대해 간략히 설명하자면, 만약 Memtable에 사용 가능한 공간이 없으면, RocksDB는 잠겨지고 상태가 변경되어 더 이상 업데이트가 불가능한 immutable 상태가 된다. RocksDB는 immutable Memtable이 되어 더이상 업데이트를 허용하지 않는 경우가 될 때, 해당 Memtable에 사용 가능한 공간이 없으면 다른 Memtable로 전환한다. 그리고 background에서 Memtable의 데이터를 SSTFile로 변환하여 L0에 기록하면서, 다음 Put 요청을 위해 새로운 Memtable을 할당한다. Memtable을 가능한 빨리 메모리에 보관하는 것이 중요하기 때문에, Memtable을 L0로 변환하는 작업은 정렬되지 않은 순서로 이뤄지며 순서에 상관없이 처리된다. 따라서, L0에는 같은 key에 대한 여러 SSTFile이 포함될 수 있다. 나중에, L0의 SSTFiles는 LSM KV의 내부 작업에 의해 하위 level의 storage space인 L1으로 이동된다.
반면, Get request는 특정 키(given key)와 연관된 value에 대한 series of reads를 함께 가져온다. RocksDB는 먼저 Memtables에서 key를 검색하고 해당 key에 대한 value를 제공한다. Memtables에서 key를 찾을 수 없는 경우, RocksDB는 L0에 저장된 모든 SSTFiles를 스캔하고 key를 찾는다. (+참고7) 이것은 파일이 unsorted way로 저장되기 때문에 L0에는 해당키에 일치하는 여러 SST 파일이 존재할 수 있기 때문이다. 만약 RocksDB가 L0에서 key를 찾지 못하면, L1으로 이동해서 다시 검색한다. L1의 SSTFiles는 L0에서 compacted되어 만들어지므로 각 files은 unique(고유한) key를 포함하고 있어, RocksDB가 target KV pair를 빠르게 검색할 수 있게 된다. L0의 unsorted data structure는 RocksDB가 빠르게 in-memory buffer를 보호할 수 있게 (+참고8) Put against stalls를 방지하지만, Get 서비스에서 많은 storage access (reads)를 발생시키는 단점이 있다.
Internal tasks.
Figure 1b는 LSM KV의 internal task 와 그것과 관련된 주요 software components를 보여주는 상세한 절차를 보여준다. Memtable은 volatile memory media의 performance advantage를 살리기 위해 잘 설계되었지만, 전원 공급 장애가 발생하면 데이터가 손실될 수 있다. RocksDB는 Memtable 업데이트 전에 KV pair를 logfile 형태로 underlying storage안의 지정된 영역인 write-ahead log (WAL)에 기록하여 persistent와 durable(내구성)을 확보한다. WAL은 Memtable 업데이트 이전에 지정된 영역인 write-ahead log에 logfile 형식으로 KV pair를 쓰기위해 수행되며, 이는 crash consistency control을 위해 underlying file system의 (+참고9) page cache를 bypass(우회)하여 synchronous operation을 수행한다. RocksDB가 WAL에 KV pair를 기록하는 것은 시간이 많이 소요되기 때문에, RocksDB는 Memtable 앞에 위치한 또 다른 내부 버퍼인 write group을 사용한다. 이 과정에서 RocksDB는 Memtable과 L0의 space utilization(공간 이용률)을 체크하고, available space가 없는 경우, Memtable과 L0 SSTFile 각각을 reclaim하기 위해 flush and/or compaction 작업 항목을 대기열에 넣는다. 이러한 항목에는 space reclaiming(공간 회수)를 위한 적절한 포인터가 포함되어 있으며, 이 작업은 RocksDB의 background thread에 의해 모두 수행된다. Memtable flush를 위해, internal task는 Memtable의 모든 key를 확인하고, SSTFile을 빌드한 후 L0로 flush한다. L0 compaction의 경우, 해당 internal task는 target SSTFile을 선택한다. 예를 들어, Figure 1c를 고려해보면, 해당 SSTFile의 key range는 60에서 120까지이다. 이 작업은 또한 compaction target`s keys와 연관된 L1`s SSTFiles(그림에서 각각 80~90과 100~140을 가진 두 개의 L1 SSTFiles)를 선택한다. 그런 다음, 모든 세 개의 SSTFile 항목을 확인해서 latest information만 남게 하여 merge sort (병합 정렬)을 수행하고 새로운 L1 SSTFile을 생성한다. 마지막으로, RocksDB는 새로운 SSTFile을 synchronously write하고 기존 3개의 SSTFiles를 underlying SSD에서 삭제한다.
SSD Internal Tasks and Challenges

Internal DRAM flush.
SSD의 flash write는 flash read에 비해 x N배로 느리기 때문에, high-performance SSD는 대용량의 internal DRAM을 사용하고, (+참고10)SSD의 firmware가 buffers the writes. 예를 들어, 본 논문의 기준이 되는 NVMe hardware는 3GB의 DRAM을 사용하여 buffering하고 caching한다. 이러한 buffered write은 # bandwidth(대역폭)을 높이기 위해 특정 액세스 패턴으로 주기적으로 storage backend로 flush된다. 따라서, 일정 기간 동안 write가 전혀 없더라도 (이전에 버퍼링된) 데이터를 storage backend로 이동시키는 것은 들어오는 읽기 작업에 영향을 미칠 수 있다. ( disk나 SSD에 대한 접근을 필요로 하기 때문에 들어오는 read operation에 영향을 미칠 수 있다.) . Figure 2a는 SSD의 internal flush에 의해 영향을 받는 read latency를 보여준다. 테스트 기간 동안 조건은 without any write operation이고 4KB 크기의 sequential read requests만 발생시켰고, 테스트 전에 64MB block을 SSD에 기록했다고 한다. 그림에서도 볼 수 있듯이, 기준이 되는 NVMe hardware는 대규모 latency spike에 시달리고, 대부분의 경우 일반적인 latency보다 최대 7.75배 높다. 그리고 read-only time 동안 latency도 크게 변동한다. 이는 internal flush에 의해 생긴 write가 완료될 때까지 read를 stall(막히게)하므로 발생한다.
Internal flushes는 오로지 firmware에 의해서만 관리되기 때문에, host software components는 read의 latency consistency를 제어할 수 없다는 점을 유의해야한다. 위에서 분석한 latency의 변동을 제거하려면, host와 firmware 간에 tight collaboration이 필요하다.
Garbage Collection.
flash는 erase-before-write와 read/write and erase에 대한 asymmetric I/O # granularity 등 unique한 device-level characteristics를 가지고 있다. 이러한 특성 때문에 SSD의 firmware는 its actual location 즉, 실제 위치가 아닌 미리 지워진 free block에 들어오는 데이터를 쓰게 된다. 업데이트되지 않은 데이터의 주소 remapping (translation)으로 flash가 기존 block device와 호환되지만, free block이 없는 경우 Garbage Collection을 수행해야한다. GC는 수백 개의 page를 포함하는 flash block을 기반으로 수행되므로 target block에 있는 valid data를 안전하게 new location of a block으로 옮겨줘야한다. 이 internal task는 flash write보다 더 긴 block erase operation을 도입하며, 이전 blcok에 있는 valid data를 새 block의 새 위치로 안전하게 이동하기 위해 많은 read/write operation이 필요하다. 이 operation은 long latency와 작업이 완료될 때까지 들어오는 많은 request를 stall한다. Figure 2b는 GC를 수행하는 동안(195초부터) read latency를 보여준다. 이 테스트에서, read는 sustainable latency(16.2 us)를 보여주지만, GC가 시작되면 latency가 급격하게 증가하여 최대 9.8 ms까지 도달한다.
이러한 internal tasks들은 read performance를 상당히 저하시키지만, 이것 모두 더 많은 request를 위한 더 많은 사용 가능한 공간을 보장하고 storage backend의 reliability를 관리하기 위해 필수적인 작업이다. 이러한 작업들은 단순이 host 측 software modules에서 제거하거나 schedule할 수 없다.
Read-Reclaiming
Flash는 low-level에서 read services에 대해 매우 최적화되어 있지만, read-only scenario에서도 특정 상황에서 data migration과 block erase operation을 도입할 수 있다. 특히, erase없이 block의 일부 page를 계속해서 읽는 경우, any write도 없이 block에 stress를 가하고 block 내에 있는 모든 데이터에 영향을 미친다. 이러한 read disturbance(읽기 간섭)은 유감스럽게도 종종 (+참고11) parity-check code(ECC 및 LDPC)로 수정할 수 있는 범위를 초과하는 error rate를 증가시킨다. 이러한 read disturbance issue를 해결하기 위해, underlying firmware (하부 firmware)는 일정 기간 동안 intensive하게 작동한 block을 주기적으로 reset(erase)해야 한다. firmware가 block을 지우면, 그 내부 상태는 normal state로 돌아가게 되고, 해당 block은 이후의 read로 인해 가해지는 stress를 다시 견딜 수 있게 된다. block을 지우기 위해서는 target의 기존 existing data를 읽고 그것들을 모두 새로운 block으로 복사하는 작업이 필요하다. Figure 2c에서 보여지는 것처럼, 이 internal task인 read reclaiming은 read performance를 심각하게 악화시킬 수 있다. 이 테스트에서는, 사전 조건으로 특정 block set을 intensive하게 4번 read한 후, random I/O pattern으로 다시 읽은 것을 simulation한 것이다. 그림에서도 확인할 수 있듯이, read reclaiming에 의해 영향을 받은 read latency는 typical case보다 32qo rls 2.5ms까지 증가하는 것을 볼 수 있다.
만약 underlying SSD를 read-dedicated storage로만 사용한다 하더라도, read reclaiming에 의한 long-tail latency는 불가피하고, 따라서 LSM KV의 read service에서 이러한 latency가 critical path에서 벗어나도록 새로운 interface와 firmware 지원을 고안하는 것이 필요하다.
Motivation and Related Work

Long-tail Latency on Reads
Figure 3a는 Facebook와 Yahho의 다양한 RocksDB usage scenario에 대한 Get latency의 Cumulative Distribution Functions(CDF)를 보여준다. 이번 평가에서는, 본 논문에서 수정할 baseline 1.92TB NVMe hardware에서 RocksDB 6.23을 사용한다. 이 baseline은 64 layer TLC NAND flash를 포함하며, 이것은 여덟 개의 다른 채널에 연결되어 있다.
Significance of long-tail latency
Flash의 low device-level latency 덕분에, 이들의 nominal performance trend는 서로 유사하다. 모든 Get latency는 200us 미만이다. 하지만 Get latencies는 P99, 99.9th percental에서 몇 ms에 이르며, 모든 경우의 latency는 normal Get latency 대비 최대 15.7배 증가한다. 본 논문의 저자들이 테스트한 모든 RocksDB usage scenarios에서 이러한 long-tail latency가 발견된 주요 이유는 database나 kerenl computation에서 비롯되는 것이 아니라, heavy storage access 때문이다. 자세히 말하면, 저자들은 Facebook의 social graph data processing workload인 UserDB의 execution time을 Get의 storage latency (Storage), client computaion times (App), database latency (RocksDB), and kernel latencies (Kernel)로 분해했다. Figure 3b에서 보여주듯이, (+알아볼참고1)LSM KV의 software stack의 계산은 Get의 long-tail latency에서 중요한 역할을 하지 않는다. 그러나 Storage가 total execution time의 87%를 차지하여 꼬리 부분에서 Get service time을 대다수 차지한다. software stack의 latency computation은 Storage(total execution time의 절반)와 균형적으로 잘 조절되어 있지만 LSM KV의 heavy I/O requests는 Memtable과/또는 SSTFiles을 reclaim해야할 때 Storage의 비율을 급격하게 높인다.
Internal tasks' performance impacts.
Figure 3c는 UserDB workload의 시간 순서로 분석한 것을 보여주며, UserDB와 동일한 I/O pattern을 보이지만 Put queries를 제거한 이상적인 Get-only workload와의 read characteristic을 비교한다. 이 분석에서는 RocksDB가 Memtable을 flush할 때 (596K index에서), baseline read latency가 147us에서 2.97ms로 증가하고, read latency가 어느 정도 시간이 지나야 정상으로 돌아오는 것을 확인할 수 있다. RocksDB의 SSTFiles를 compaction하기 시작하면, 많은 read and write operations이 KV pairs을 merge하기 위해 수행되므로, 들어오는 Get request를 막게 되어 normal case(일반적인 경우)보다 30배 긴 latency를 보이게 된다. WAL에서 parallel하게 수행되는 read의 latency는 그다지 크지 않지만, WAL도 일반적인 경우에 비해 Get latency를 10.6배 안좋게 만든다.
Scheduling Internal Tasks

Challenges of system-level approaches.
RocksDB의 internal task에 의해 생기는 performance degradation을 해결하기 위한 많은 연구들이 있다. 예를 들면 TRIAD, PebblesDB, SILK 등등. 이러한 접근 방식들은 여러 최적화 지점을 가지고 있지만, 일반적으로 flush 및 compaction을 idle time이나 다른 사용 가능한 시간으로 rescheduling하거나 delay시켜서 long-tail latency를 제거하려한다. 이러한 system-level 접근은 LSM KV의 internal tasks에 의해 도입된 read/write overhead를 어느 정도 숨길 수 있지만, SSD의 내부 작업을 처리할 수 없으며, 예약으로 인해 발생하는 부작용 때문에 Get service의 long-tail latency를 완전히 제거할 수 없다. 특히, compaction을 연기하면 들어오는 Put service의 suspending time을 제거하지만, LSM KV의 L0는 데이터 이전 없이 SSTFiles를 누적하여 L1의 Get latency를 증가시킨다. Figure 4a는 compaction rescheduling이 적용된 경우와 아닌 경우 각각의 Get service의 tail latency trend를 비교한다. RocksDB의 SSTFiles를 적절한 시간에 압축하는 경우, Get tail latency가 지속적으로 관리된다(lower than 1 ms). 그러나 delayed compaction으로 서비스되는 Get의 tail latency는 계속 증가하여 3.1ms에 이르며, RocksDB compaction의 no-scheduling case보다 3.6배 길어진다. 이는 Get service가 RocksDB의 L0의 처음부터 끝까지 적절한 값 (input key와 짝을 이루는 value)을 찾아야하기 때문이다. L0의 SSTFiles은 정렬되어 있지 않기 때문에, KV searching은 많은 미해결된 read를 도입해서 tail latency를 증가시킨다.
반면에, Figure 4b에서는 RocksDB의 delayed flush도 Get의 tail latency를 최대 27.4배까지 증가시킨다. Get의 tail latency가 rescheduled된 compaction보다 더 심각해 보이는 이유는 Memtable flush를 지연시키면 Memtable 관리에할당된 모든 in-memory spaces를 소모하기 때문이다. 따라서, RocksDB의 write operation을 모두 멈추고 Memtable을 확보할 때까지 대기하기 때문에, Get service가 심각하게 중단되는 것으로 나타난다.
Device-level latency determinism and limits.
이미 언급된 SSD's internal tasks는 serious performance drop과 long latency를 보이는 것으로 잘 알려져 있다. internal tasks가 무작위적인 시간 간격(arbitrary time period)으로 호출되므로, 다양한 computing domains에서 많은 제품들이 환경 내에서 latency-critical application을 배포하기 어렵게 만든다. 최근에, standard NVMe protocol은 predictable and deterministic한 latency를 제공하기 위해 predictable latency mode(PLM) interface를 도입하였다. PLM은 SSD가 deterministic performance window (DTWIN) 또는 non-deterministic performance window (NDWIN) 중 하나에서 작동하도록 제안한다. NVMe specification에 따르면, NDWIN은 다음 DTWIN을 준비하는 시간이다.
PLM interface는 단순한 interface protocol의 일부로, deterministic latency를 보장하기 위한 구체적인 요구사항이나 디자인 세부사항을 강제하지는 않는다. 이러한 새로운 interface는 SSD의 예측 불가능한 동작을 잘 관리하는 방법에 대한 blueprint를 제시하지만, PLM은 실제로는 # soft latency determinism만을 지원하는 최선의 노력 계약이다. 예를 들어, SSD의 internal tasks는 flash characteristics를 숨기기 위해 필연적으로 호출되므로 DTWIN과 항상 적절하게 작동시키는 것은 불가능하다. 만약 underlying hardware가 최대한의 노력으로 SSD's internal tasks를 숨기는 이상적인 경우라 하더라도, host-side LSM KV의 동작 방식에 따라 언제든지 latency determinism이 쉽게 깨질 수 있다. strong latency determinism을 지원하기 위해서는, host-side LSM KVs와 underlying storage간의 긴밀한 collaboration이 필요하다.
High-level View of Vigil-KV
본 논문의 주요 목표는 Get Sevices에서 long-tail latency가 없는 LSM KV system을 보장하여 read performance가 deterministic하고 consistent하게 만드는 것이다. LSM KV 또는 SSD의 internal task만 scheduling하는 것만으로는 strong latency determinism을 달성할 수 없으므로 Vigil-KV는 hardware와 software를 co-design approach한 방식을 취한다. 특히, Vigil-KV hardware는 host가 LSM KV에 strong latency determinism을 통합하는 것을 허용하는 basic scheduling block을 제공하기 위해 설계된다. Vigil-KV의 software part는 LSM KVs의 요청을 runtime에서 분류하고, underlying hardware가 제공하는 scheduling block을 완전히 활용하여 적절하게 할당한다. hardware와 software의 co-design approach(공동 설계 접근법)은 client-side Get queries의 latency를 consistent하게 deterministic으로 만들고 언제나 long-tail을 가지지 않게 할 수 있다.
Hardware Support for Fine-Granular Performance Window
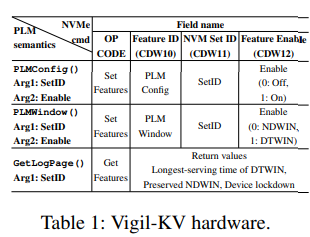
PLM interfaces.
Table 1에서 볼 수 있듯이, Vigil-KV hardware는 device states를 정확하게 scheduling할 수 있도록 host-side Vigil-KV software가 사용할 수 있는 PLM interface를 구현하고 제공한다. 본 연구의 PLM interface가 제공하는 기능은 크게 3가지로 분류된다. 1) PLM 설정(PLMConfig()), 2) NDWIN 및 DTWIN 구성 (PLMWindow()), 그리고 3) device log # queries(디바이스 로그 조회) (GetLogPage()). 해당 table에는 host-side kernel driver가 NVMe feature commands를 사용하여 이 세 가지 의미를 구현하는 방법도 포함되어 있다. 예를 들어, LSM KV system의 kernel driver는 NVMe의 setfeature을 통해 feature ID (PLM 구성)와 활성화 flag (on/off)를 구성하여 target storage의 PLM mode를 켜거나 끌 수 있다. 비슷한 방식으로 Vigil-KV hardware의 performance window를 PLMWindow()를 사용하여 간단하게 구성할 수 있다. 참고로 여기서 window는 DTWIN 혹은 NDWIN을 의미한다. GetLogPage() 함수를 사용하여 device state/condition information을 조회하면, Vigil-KV hardware와 LSM KV system이 통신할 수 있으며, 결과는 512B data package(log page)로 return된다. 주어진 performance window information을 기반으로, Vigil-KV hardware는 가능한 한 SSD의 internal tasks를 수행하기 위해 NDWIN을 우선적으로 처리하며, internal tasks가 DTWIN에 schedule되지 않도록 보장한다. 앞에서 봤듯이, SSD의 internal tasks는 영원히 지연될 수 없으므로, 저자들은 DTWIN의 longest-serving time을 규제하고 이를 GetLogPage를 통해 호스트에 보고한다. Vigil-KV hardware는 SSD의 internal tasks를 처리할 최소 NDWIN 시간을 정의하고 log page를 통해 host에 노출시킴으로써, SSD의 internal task를 처리하는데 필요한 최소 시간을 host가 알 수 있도록 한다. 따라서, Vigil-KV software는 이 정보를 활용하여, log page를 참조해서 performance window를 절절하게 scheduling할 수 있다.
NVM multi-set architecture.
host에 다양한 performance scheduling option을 제공하기 위해, hardware는 backend storage를 multiple volume으로 분할하여 각각 별도의 PCIe 물리적 함수로 host에게 노출하는 NVM multi-set을 도입한다. Vigil-KV hardware는 NVM set이라고 불리는 각각의 physical function에 PLM interface를 활성화하고, 각각의 set에 대해 다른 logic/core를 할당하여 독립적으로 작동하게 한다. 이 NVM nulti-set architecture는 host-side LSM KV's software components에 최대의 flexibility를 부여해서 underlying device states (DTWIN과 NDWIN)를 더 세밀하게 scheduling할 수 있다. 예를들어, LSM KV system은 NVMe의 set-feature의 NVM Set ID (NVMe 명령어의 codeword 11)를 다르게 구성함으로써 단일 NVMe device내에서 다른 performance windows를 구성할 수 있다.
Software-Defined Strong Latency Determinism for Get services.
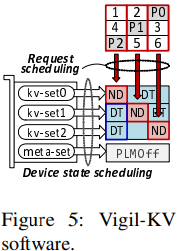
Figure 5는 Vigil-KV software가 Vigil-KV hardware가 제공하는 더 세분화된 performance windows를 활용하여 strong latency determinism을 달성하는 방법을 보여준다. 이는 세가지 주요 논리적 구성요소로 이루어져 있다. 1) metadata separation 2) device state dcheduling, and 3) request scheduling
Managing data, devices, and requests.
Vigil-KV software는 storage volume에서 (+알아볼참고 physical function의 역할)physical function을 제외하고 metadata management를 위해 내부적으로 할당하며, 이를 meta-set이라고 한다. 이 meta-set의 PLM은 PLMConfig()에 의해 비활성화되며, Vigil-KV software는 metadata 관련 request를 meta-set으로 전달함으로써 LSM KV의 정규 queries와 WAL 및 journaling activities를 분리한다. metadata separation을 통해 kv-sets이 crash consistency management를 위한 heavy internal writes에 방해받지 않도록하여, 우리의 device state와 request scheduling mechanism이 Get service의 strong latency determinism을 주로 제공할 수 있다.
한편, Vigil-KV hardware가 노출하는 physical function들은 kernel level에서 들어오는 LSM KV의 query request를 처리하도록 할당한다. 이를 kv-sets라고 한다. Vigil-KV software는 그 다음 모든 kv-set 장치 상태 (즉, performance windows)를 schedule해서 언제든지 n-1 kv-sets이 DTWIN에 있도록 하면서 (PLMWindow()를 사용) NDWIN이 균등하게 scheduling(Round-Robin 방식으로)될 수 있도록 허용한다. n은 Vigil-KV가 SSTFile 관리에 할당할 수 있는 total number of physical functions을 의미한다. Vigil-KV software는 LSM KV의 internal tasks와 client request를 runtime에 분류하고, underlying device에서 구성된 performance windows를 알고 있어서 서로 다르게 scheduling한다. 구체적으로, 모든 client requests는 DTWIN으로 구성된 n - 1개의 kv-sets에서 서비스되도록 schedule된다. Vigil-KV software는 LSM KV의 internal tasks에서 오는 모든 request를 NDWIN에 의해 예약된 kv-set에서 예약하지만, 너무 많은 internal tasks' requests로 인해 NDWIN이 너무 길어지지 않도록 internal tasks' requests 수를 제한해서 항상 n - 1개의 kv-set이 DTWIN으로 구성되도록 한다. 후에 해당 device state와 request scheduling의 세부 정보를 설명한다.
Data reconstruction for NDWIN.
Vigil-KV는 LSM KV의 모든 작업과 SSD의 internal 작업을 NDWIN으로 밀어 넣으며, 다른 kv-set에서 round-robin manner(방식)으로 schedule된다. LSM KV와 SSD의 internal task를 처리하는 동안 NDWIN 상에서 request를 처리하는 것은 LSM KV와 SSD 모두에게 필수적이지만, 특히 NDWIN으로 scheduling된 kv-set을 대상으로 하는 client request, 특히 Get services는 차단될 수 있으며, 이로인해 long-tail latency가 발생할 수 있다. 이를 해결하기 위해, Vigil-KV는 NDWIN에서 internal tasks와 함께 # parity bits를 # encode한다. 특히, Vigil-KV는 SSTFile을 저장할 때, 해당 파일을 여러 개의 # chunk로 나누고 이러한 chunk를 NDWIN에서 kv-set을 걸쳐 # striping한다. Vigil-KV는 언제나 n - 1개의 kv-set이 DTWIN으로 구성되도록 보장하므로, Vigil-KV는 다른 kv-sets에서 데이터를 읽어 원래 데이터를 재구성하고 NDWIN kv-set을 건드리지 않고 서비스를 제공한다. 이 "array-level" memory와 storage techniques에서 영감을 받은 data reconstruction (데이터 복원 기술)은 분명히 Get services의 long tail latency를 제거할 수 있지만, 모든 kv-sets을 consistent하게 DTWIN으로 만드는 이상적인 storage와 비교하여 평균 latency를 증가시킬 수 있다. 따라서, Vigil-KV는 physical function level에서 불필요한 data reconstruction을 피하기 위해 NDWIN을 최소화한다. 저자들의 계획에서 parity bits는 per SSTFile이 아닌 per chunk로 생성되기 때문에, compaction 후에도 parity를 다시 계산할 필요가 없다. 이 기술과 구현의 설명은 후에 다룬다.
Hardware Prototype and Characterizations
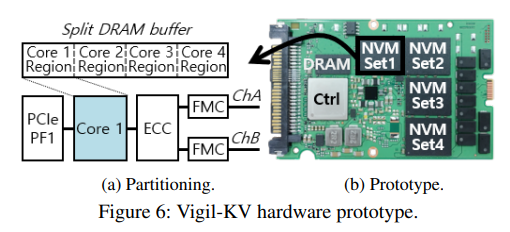
Enabling PLM with NVM Multi-Sets
Partitioning an SSD.
현대 SSD는 많은 flash packages를 사용하며, 이러한 package들은 channel이라고 불리는 여러 개의 메모리 버스를 통해 다중의 embedded cores에 연결된다. (+알아볼참고 FMC에 대한 것)각 channel당 모든 flash package는 특정한 micro-coded controller인 flash memory controller (FMC)에 의해 관리된다. 예를 들어, 본 논문의 baseline hardware (SSD)는 여덟 개의 flash package를 포함하며, 각 package에는 여덟 개의 flash memory banks가 있으며, 모두 여덟 개의 channel과 FMS를 통해 네 개의 코어에 연결된다. 각 FMC가 자체적으로 관리하는 hardware를 가지고 있기 때문에 저자들은 baseline hardware를 수정하여 single storage space를 multiple spaces로 분할한다. 특히, Figure 6a에서 보여지듯, 저자들은 각 코어를 두 개의 FMC에 배정하고 모든 코어를 독립적인 (별도의) physical function으로 작동하도록 수정한다. 각각의 physical function이 서로 간섭하지 않도록 하기 위해, 내부 DRAM space를 균등하게 분할하여 각각 다른 physical function에 할당한다. Figure 6b는 Vigil-KV hardware의 prototype을 보여준다. 네 개의 physical function이 있으며 각각은 host에 의해 다른 # identifier로 지정될 수 있다.(Table 1에서의 NVM set ID도 identifier의 종류이다.) Flash firmware는 코어 별로 # instantiate되어, physical function은 다른 physical function에 의해 방해받지 않는다.

Integrating PLM.
DTWIN을 구현하기 위해, Vigil-KV hardware의 각 firmware는 host 명령 제어와 내부 작업 관리에 연관된 여러 개의 queue를 사용한다 (Figure 7a). Internal job queue (내부 작업 큐, IJQ)는 주소 변환을 관리하는 firmware module 전용되고, legacy I/O queues (기존 I/O 큐, LIQ)는 host(NVMe) interface를 관리하는 firmware 부분에 할당된다. Vigil-KV hardware에서 request는 legacy와 internal task로 분류되며, IJQ와 LIQ를 사용하여 다르게 처리될 수 있다. DTWIN으로 구성된 경우 (PLMWindow()를 사용하여), Vigil-KV hardware는 우리의 firmware가 LIQ에서 온 request만 처리하고, IJQ의 모든 request를 Foreground 및 background에서 중지한다. 이 device는 SSD의 internal tasks에 중단없이 들어오는 (client) read requests를 즉시 처리할 수 있다. IJQ의 요청이 더이상 처리할 수 있는 공간이 없으면, firmware는 request를 일시 중단할 수 없으며, 이는 host가 DTWIN을 적잘하게 scheduling해야 함을 의미한다. 곧 자세히 이 constraints에 대해 설명하겠다.
PLM Constraint and Behavior Analysis
DTWIN/NDWIN conditions.
resource 분할과 queue isolation(큐 격리) (IJQ/LIQ)는 SSD의 internal tasks가 주는 read latency spike를 제거할 수 있지만, deterministic latency를 일관성있게 만드는 것은 그렇게 간단하지 않다. 이것은 host와 strong collaboration이 필요하다. 이전 NDWIN state에서 buffering된 write가 있을 경우, DTWIN에서의 read service는 간섭을 받는다. Vigil-KV의 firmware는 명시적으로 internal buffer를 flush하고 DTWIN으로 이동하기 전에 buffer를 더이상 쓰지 않도록 비활성화하여, 이전 NDWIN 상태에서 buffering된 write로 인한 간섭을 제거한다. DTWIN을 더 적은 제한된 상태로 제공하는 것이 우리 hardware가 달성하고자 하는 미션이지만, DTWIN에서의 I/O service 중에는 어떤 데이터도 손실되지 않아야 한다. 그렇기 때문에 DTWIN 이전과 DTWIN 중간에 internal buffer를 지우고 buffer를 우회해야 한다. internal buffer의 flush중에 host는 데이터를 명확하게 삭제하기 위해 데이터를 추가적으로 쓰지 않아야하며, 이것을 device lockdown condition이라고 한다. Figure 7b는 이전 NDWIN에서 얼마나 많은 데이터가 쓰였는지에 따라 device lockdown time이 다양하게 변하는 것을 분석한다. 저자들이 테스트한 모든 워크로드는 NDWIN 중에 수십 MD의 데이터를 기록한다. host가 데이터를 20ms미만으로 보유하면 충분하다. 비슷하게, DTWIN에서 write이 있는 경우, 본 논문의 hardware는 written data의 strong durability와 consistency를 보장하기 위해 performance window를 DTWIN에서 NDWIN으로 return 한다. host는 DTWIN에 기록 중인 write operation이 없는지 확인하여 DTWIN의 write-free condition을 보장한다.
DTWIN은 기존 flash firmware가 제공하는 현재 level의 안정성 관리(reliability management)에 영향을 미치지 않아야 한다. 구체적으로, write나 internal task가 없어도 read 간섭 문제로 인해 underlying flash media가 read로만 stress를 받게 된다. 그러므로, Vigil-KV hardware는 특정 블록에서의 과한 read가 해당 블록에 있는 모든 페이지 데이터를 손상시킬 수 있는 최악의 경우를 고려해서 DTWIN의 가장 긴 time window인 maxDTWIN을 조절한다. 마찬가지로, NDWIN은 SSD internal tasks (data migration과 block erases) 및 maxDTWIN 동안 IJQ에 누적된 요청을 완료하는 최단 시간을 나타내는 minNDWIN의 특정 시간 동안 계속되어야 한다. maxDTWIN과 minNDWIN 기간은 IJQ가 SSD의 internal tasks를 queue에 넣는 제한 때문에 강력한 상관관계가 있다. Vigil-KV hardware에서는 maxDTWIN과 minNDWIN 기간을 고려해서 fair-scheduling condition을 만족하도록 해서 DTWIN과 NDWIN을 공정하게 scheduling해야 한다. 초기 profile을 기반으로 maxDTWIN과 minNDWIN을 각각 60초와 4초로 구성하였다.
모든 이러한 정보들, 예를 들어 device lockdown time, maxDTWIN, minNDWIN은 GetLogPage() 명령을 통해 host에게 노출된다. (Table 1 참조)
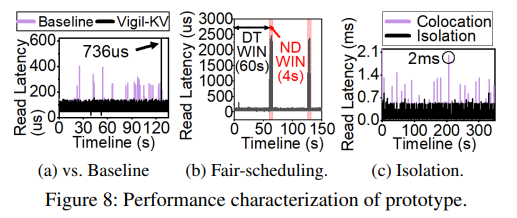
Performance characterization and validation.
Figure 8a는 baseline device와 Vigil-KV hardware prototype 간의 read latency trends를 비교한다. baseline device는 여러 개의 latency spike ( ~402us)가 나타나는 반면, Vigil-KV hardware에서는 평균 74us로 모든 read operation이 처리되며 latency는 200us 미만임이 보장된다. 128초에서 PLMWindow()를 호출하여 DTWIN을 NDWIN으로 변경하면, SSD의 internal tasks가 해당 performance window에서 정확하게 예약되기 때문에 read latency가 최대 736us까지 증가한다. Figure 8b는 DTWIN과 NDWIN을 fair-scheduling(공정하게 scheduling)하여 여러 DTWIN에서 언급된 performance behaviors(성능 동작)이 모두 보장되는 것을 보여준다. 동시에 hardware는 NDWIN에서 누적된 internal tasks를 처리하는데 바쁘다. 마지막으로, Figure 8c는 read와 write를 하나의 storage space(저장 공간)에 함께 두는 baseline device와 간섭을 여러 physical functions 간에 isolation하는 Vigil-KV hardware와 비교한다. 이 그림에서 볼 수 있듯이, baseline device의 read latency는 심하게 흔들리며 2ms까지 올라간다. Vigil-KV hardware에서의 physical function에서 read latency는 해당 physical function에 대한 PLM interface를 끄더라도, 다른 physical function으로 향하는 write로 인해 방해받지 않는 것으로 나타났다. 이는 각각의 physical function을 완전히 다른 resource로 분할했기 때문이다. Vigil-KV의 software는 이러한 performance isolation (성능 분리)를 metadata management에 활용하여 kv-set이 WAL을 write하고 underlying storage로 journaling을 하면서 write-free condition (write없는 상태)을 관리하지 않아도 되게 만든다.
Detail of Vigil-KV Software
PLM management에 대한 constraints(제약)이 있지만, Vigil-KV hardware는 NVM set에 mapping되는 서로 다른 physical function을 더 세분화된 방식으로 performance windows를 scheduling할 수 있는 기회를 제공한다. Vigil-KV software는 metadata management를 포함한 LSM KV의 internal tasks를 client Get service와 분리하고, 이러한 작업들을 SSD의 internal tasks와 함께 NDWIN에서 scheduling한다. 또한, 데이터를 제공할 수 없는 경우 software는 데이터를 재고성함으로써 LSM KV가 strong latnecy determinism을 제공하는 DTWIN을 일관되게 가질 수 있도록 한다.

Vigil-KV Stack Implementation
Figure 9는 Vigil-KV software stack의 구현을 보여준다. RocksDB는 존재하는 file system interface를 통해 Vigil-KV hardware와 연결되며 /dev/kv에서 SSTFile 관련 service를 수행한다. file system 하위에는, 저자들은 reqd와 devd 두 개의 kernel thread로 동작하는 Vigil-KV driver를 배치하고, 각각 block I/O(bio) request와 hardware device state를 scheduling한다. Vigil-KV driver는 시스템 초기화 시 Vigil-KV hardware가 노출하는 여러 physical function을 서로 다른 NVM set( meta-set과 kv-set)에 매핑한다. reqd는 linux의 기존 multiple device md driver와 유사하게 데이터 청크와 bio를 다른 kv-sets로 striping하지만, underlying device state를 인식하면서 scheduling한다. 구체적으로 reqd는 스케줄된 bio request가 DTWIN의 write-free condition을 충족하는지 확인한다. 또한, reqd는 LSM KV의 internal tasks로 인해 client의 read request가 지연되지 않도록 데이터를 재구성을 실시함으로써 요청된 bio가 DTWIN의 write-free condition을 충족하도록 보장한다. 반면, devd는 fair-scheduling condition과 device lockdown time을 고려해서 kv-sets의 장치 상태를 scheduling한다. 이 device state scheduling에 대한 자세한 설명은 곧 나올 예정이다.
Vigil-KV driver는 read latency를 예측 가능하게 하기 위해 Linux page cache 및 block layer를 우회하도록 구성되어 있다. 이것은 read latency를 어느 정도 흔들리게하거나 관리하기 어렵게 만들 수 있다. 예를 들어, kv-sets은 내부적으로만 관리되므로, kv-sets에 대한 bio 구조(e.g., logical block address and offsets)는 page cache가 관리하는 bio request와 다르다. Vigil-KV driver는 대신 plm_cache라는 내부 buffer를 사용하여 linux stripe 목록 형식으로 kv-sets의 bio 요청을 버퍼링한다. plm_cache 크기는 부팅 시 사용자가 kernel parameter로 구성할 수 있다. reqd는 포함된 bio request를 underlying kv-sets로 scheduling할 때 stripe requests를 사용한다. Vigil-KV driver는 page cache를 우회하기 때문에, RocksDB에 plm_sync system call (file system의 fsync의 변형)을 제공한다. plm_sync는 LSM KV의 internal tasks로 인해 Memtable, Wal 및 SSTFile이 삭제되기 전에 Vigil-KV driver가 plm_cache를 완전히 flush하는 것을 보장한다. Vigil-KV driver가 block layer를 bypass하고 NVMe driver와 직접 통신하는 이유는 block layer의 bio 병합(merging)과 ordering(정렬)이 determinism을 깰 수 있기 때문이다. 예를 들어, LSM KV의 internal tasks request는 NDWIN에 의해 예약되어 있지만 block layer에서 DTWIN에 대해 발행될 수 있다. LSM KV에서는 reqd가 LSM KV의 internal tasks와 client request를 다르게 스케줄링하므로, LSM KV에서 우선순위 정보를 Vigil-KV driver에 전달해야한다. 이를 위해, 저자들은 RocksDB와 journaling block device daemon (jbd2)에 작은 수정을 했으며, 다른 LSM KV에 쉽게 적용될 수 있다. RocksDB가 background threads를 생성할 때, 'internal task'로 I/O priority를 구성하는 ioprio_set system call을 수행한다. ioprio_set 함수는 우선순위를 'internal task'로 설정하기 위해 호출되며, 이 우선순위 정보는 process control block, task_struct의 io_context에 저장하여 전달된다. Get queries와 WAL은 모두 RocksDB의 동일한 thread에서 관리되므로, 우리는 WriteToWAL()을 수행하기 전에 ioprio_set을 호출하여 I/O 우선순위를 'WAL'로 구성하도록 Writelmpl()을 수정한다. transaction을 commit하기 전에도 journaling은 ioprio_set에 의해 분류된다. (e.g., jbd2_log_do_checkpoint()).
Performance Window Management
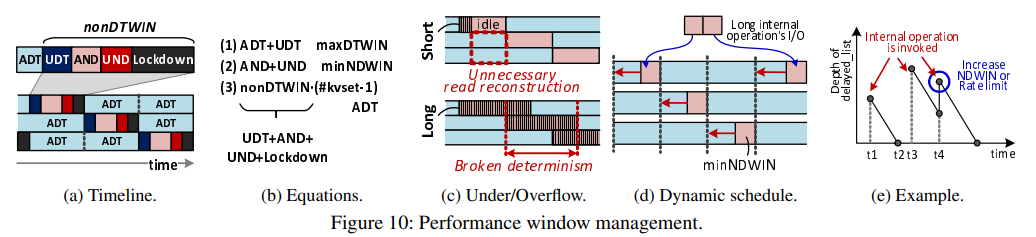
Device state scheduling.
Figure 10a에서 보여지듯이, devd는 DTWIN과 NDWIN을 스케줄링하여 항상 DTWIN으로 구성된 n-1개의 kv-sets이 존재하도록 한다. 따라서, 모든 client request는 DTWIN 또는 reqd의 데이터 재구성에서 제공된다. devd가 공정한 스케줄링과 장치 downtime constraints를 충족시키기 위해, performance windows를 scheduling할 때 두 가지 기술적인 문제가 있다. reqd는 DTWIN으로 구성된 kv-sets에서 데이터를 읽지만, 이전에 발행된 아직 완료되지 않은 읽기 요청으로 인해 읽기 요청이 지연될 수 있다. 이러한 지연된 읽기는 아직 완료되지 않은 이전의 해결되지 않은 read request 때문에 NDWIN에서 처리될 수 있으며, 이것은 strong latency determinism을 제공하지 않을 수 있다. 마찬가지로, NDWIN에 발행된 write는 SSD의 internal task로 인해 시간 지연이 발생하며 처리되지 않은 write로 인해 DTWIN에서 처리될 수 있다. 이 상황은 DTWIN에서의 write-free condition을 깰 수 있기 때문에 전자보다는 덜 바람직하다.
NVMe (Non-Volatile Memory Express)
NVMe는 Non-Volatile Memory Express의 약자로, 플래시 메모리와 같은 비휘발성 메모리를 위한 표준 인터페이스 프로토콜이다. 이는 빠른 입출력 속도, 낮은 지연 시간 및 낮은 전력 소비 등의 이점을 제공한다. 즉, 기존의 SATA 인터페이스보다 빠른 입출력 성능을 제공하는 SSD를 위한 새로운 인터페이스 기술이다. 이전의 인터페이스 기술들은 하드디스크와 같은 회전식 디스크 기반의 스토리지에 대한 것이었어서, SSD와 같은 플래시 메모리 기반 스토리지에서는 bottleneck 현상이 발생하는 경우가 많았다.
NVMe는 이러한 bottleneck 현상을 해결하고, 플래시 메모리 기반 스토리지를 최적화하여 빠른 입출력 속도와 낮은 대기 시간을 제공한다. NVMe는 기존의 SATA와 같은 하위 호환성을 가지고 있지 않기 때문에, 새로운 하드웨어와 소프트웨어가 필요하다. 그러나 이는 SSD의 최적화와 더 빠른 입출력 속도를 제공하며, 대용량 데이터 센터와 같은 고성능 환경에서 더욱 빛을 발한다.
NVMe는 multi-queue, interrupt 처리, queue-depth의 증가, 전송 프로토콜의 최적화 등을 통해 기존의 인터페이스 기술보다 더 높은 성능을 제공한다. 또한, NVMe SSD는 적은 수의 코어에서 병렬 처리가 가능해서 I/O 대기 시간을 줄이고, 전역 소모량을 줄이는 등의 기능을 제공한다.
따라서, NVMe는 고성능 컴퓨팅 환경이나 대용량 데이터 센터와 같은 곳에서 매우 중요한 기술이며, 이를 통해 더욱 빠르고 효율적인 데이터 저장 및 처리가 가능해진다.
+ (+참고6)PCI Express (PCIe)를 기반으로 해서, 직렬 데이터 전송 프로토콜로 작동한다. 이는 CPU와 플래시 메모리 간의 효율적인 데이터 전송을 위해 설계되었다. 이전의 표준 (SATA, SAS)과 달리 NVMe는 여러 개의 queue를 사용하여 병렬 처리를 지원한다.
+ 참고
(+참고1)
데이터가 디스크에 sequential하게 쓰여지는 건 물리적인 디스크의 특성상 읽기/쓰기 속도가 빠르기 때문이다. 이걸 장점으로 활용하기 위해서 LSM KVs에서는 데이터가 디스크에 순차적으로 쓰여지도록 log file을 사용한다.
예를 들어, LSM KVs에서 새로운 데이터가 추가되면, 해당 데이터는 먼저 log file에 순차적으로 쓰여진다. 이후에, log file의 일정 크기가 채워지거나 일정 시간이 지나면, log file의 내용은 메모리 내의 인덱스 구조체에 정리되어 저장된다. 이러한 인덱스 구조체를 이용해서 LSM KVs는 빠른 읽기와 쓰기 성능을 제공할 수 있다.
log file은 추가된 데이터를 빠르게 저장하기 위한 일종의 버퍼 역할을 하고, 메모리가 부족할 때에도 중요한 데이터를 안전하게 보존할 수 있다. 또한, log file은 데이터를 복원하는 데에도 활용될 수 있다. 예를 들어, 시스템 장애나 데이터 손실이 발생한 경우, log file을 이용해서 손실된 데이터를 복구할 수 있다.
+
(+참고2)
이 부분에서 작은 파일로 나누어진 LSM KVs는 순차적으로 쓰여진 파일과 비교해서 읽기 높아진다. 그 이유는 작은 파일들이 읽기 동작 시에는 작은 크기로 메모리에 로드되기 때문이다. 이렇게 메모리에 로드된 작은 파일들을 비교하면서 데이터를 검색하면 디스크에서 읽어들이는 시간을 최소화할 수 있다. 또한, 작은 파일들은 읽기 cache의 크기를 초과하지 않아서 읽기 성능을 더 향상시킬 수 있다.
그리고 LSM KVs에서는 작은 파일들을 비교하면서 데이터를 검색하는 것은 해당 데이터의 키(key) 값을 기준으로 이루어진다. 각 파일은 일정한 범위의 키 값을 가지고 있으며, 작은 파일들을 비교하면서 찾고자 하는 키 값이 해당 범위에 속하는지를 확인하고, 속한다면 해당 파일에서 데이터를 읽어오게 된다. 따라서 검색 기준은 키(key) 값이며, 데이터의 내용은 검색과는 무관하다.
+
(+참고3)
분산 시스템은 여러 대의 컴퓨터를 하나의 시스템처럼 동작하도록 구성하는 방식이다. 대규모 데이터를 처리할 때, 하나의 컴퓨터로는 처리 능력이 한계가 있다. 그래서 여러 대의 컴퓨터를 연결해서 분산 시스템을 구성하면, 데이터를 효율적으로 처리할 수 있다.
예를 들어, 검색 엔진에서는 웹 크롤링을 통해 수 많은 웹 페이지를 수집하고, 수집한 데이터를 (+참고4)색인화(Indexing)해서 검색을 빠르게 수행한다. 이런 대규모 데이터를 처리하려면 분산 시스템이 필요하다. 여러 대의 컴퓨터에서 웹 크롤링을 수행하고, 수집한 데이터를 색인화하여 여러 대의 서버에서 검색을 처리하면, 검색 엔진의 처리 속도를 빠르게 할 수 있다.
또한, 대용량 데이터베이스나 파일 시스템에서도 분산 시스템을 활용하여 데이터를 저장하고 처리할 수 있다. 여러 대의 서버에서 데이터를 분산하여 저장하면, 데이터에 대한 안정성을 높일 수 있고, 데이터에 대한 처리 성능도 높일 수 있다.
최근에는 클라우드 컴퓨팅 기술의 발전으로 분산 시스템 구성이 더욱 용이해졌으며, 기업에서는 대규모 데이터 처리를 위해 클라우드 서비스를 활용하는 경우도 많아졌다.
+
(+참고4)
색인화 (Indexing) : 데이터를 검색할 때 빠른 검색 속도와 효율성을 위해 데이터베이스에서 사용하는 기술이다. 데이터베이스에서 색인화는 검색 속도를 높이기 위해 특정 필드에 대한 정보를 모아서 별도의 데이터베이스에 저장하는 작업이다. 이렇게 저장된 데이터는 검색 요청 시 빠른 속도로 결과를 반환할 수 있다.
웹 크롤링에서는 수집한 데이터를 특정 필드별로 색인화하여 검색 시간을 단축시키는데 할용된다. 예를 들어, 검색 엔진에서는 수집한 문서를 특정 필드 (예 : 제목, 본문, 작성자 등) 별로 색인화하여 검색을 수행한다. 이렇게 색인화된 데이터를 기반으로 검색을 수행하면 빠른 검색 속도와 정확한 검색 결과를 제공할 수 있다.
+
(+참고5)
"Memory Footprints"는 메모리 사용량을 의미한다. 이는 프로그램이 실행될 때 시스템 내의 메모리(RAM)를 사용하는 양을 의미한다. memory footprints가 크면, 프로그램은 더 많은 메모리를 차지하며, 시스템에서 실행될 때 다른 프로그램에 할당된 메모리를 줄일 수 있다. 따라서, 작은 memory footprints를 가지는 프로그램은 시스템의 성능을 향상시킬 수 있다.
+
(+참고6)
"PCIe"는 Peripheral Component Interconnect Express의 약자로, 컴퓨터의 주요 구성 요소인 CPU, 메모리, 그래픽 카드 등을 서로 연결하는 고속 인터페이스이다. 이는 기존의 PCI(Peripheral Component interconnect) 인터페이스보다 빠른 데이터 전송 속도를 제공하며, 특히 대용량 데이터 처리나 그래픽 처리와 같은 고성능 작업에 적합하다. PCIe는 직렬 데이터 전송 프로토콜을 사용하여 더 많은 데이터를 더 빠르게 전송할 수 있다. 또한, PCIe는 여러 개의 데이터 전송 레인(데이터 전송 경로를 의미한다.)을 지원하여 데이터 전송의 병목 현상을 줄이고, 더 많은 장치를 연결할 수 있도록 한다. 이러한 특징으로 PCIe는 고성능 컴퓨터 및 서버, 게임 그래픽 카드 등 다양한 분야에서 사용되고 있다.
+
(+참고9)
bypass는 우회하다, 무시하다의 의미로 사용되며, 이 경우에는 page cache를 우회하여 바로 디스크에 기록한다는 의미이다. 일반적으로 파일 시스템은 데이터를 기록할 때, 메모리 내에 cache를 두고 이를 이용하여 디스크로 데이터를 보내는데, 이를 page cache라고 한다. 그러나 이번 경우에는 WAL이라는 logfile을 기록할 때, 바로 디스크에 기록하여 crash consistency control을 유지한다.
또한, synchronous operation은 해당 작업이 완료될 때까지 대기하는 방식의 입출력 방법을 의미한다. 즉, 데이터를 디스크에 기록할 때, 해당 작업이 완료되기 전까지 다른 작업을 수행하지 않고 대기하는 것이다. 이 방법은 데이터의 안정성을 보장하지만, 성능면에 영향을 미치기도 한다.
예를 들어, 디스크에 데이터를 기록하는 경우, synchronous operation을 이용하면 데이터가 완전히 기록된 후에 다음 작업을 수행하므로 데이터의 일관성을 보장할 수 있다. 그러나 다음 작업이 수행될 때까지 대기해야 하기 때문에 성능이 떨어질 수 있다. 반면, asynchronous operation을 이용하면 기록 작업을 디스크에 요청하고 다음 작업을 수행할 수 있다. 이 경우, 작업이 완료되지 않았더라도 대기하지 않기 때문에 성능이 향상될 수 있다.
+
(+참고10)
SSD는 성능을 최적화하기 위해 flash memory에 기록할 데이터를 내부 DRAM에 버퍼링하는 write buffering 기술을 사용한다. host system이 SSD에 write command를 보내면, 데이터는 먼저 SSD controller의 DRAM에 버퍼링되고, 그 후 controller는 flash memory에 write을 예약한다. DRAM에 write을 버퍼링함으로써 SSD는 flash memory의 performance와 endurance를 최적화할 수 있다. flash memory는 제한된 endurence를 가지며, 일정 횟수 이상 write operation을 수행하면 소모되기 때문이다. SSD의 firmware는 write buffering process를 관리하는 역할을 담당한다.
+
# 용어정리
# long-tail latency
Long-tail latency는 일반적으로 응답 시간에 비해 상대적으로 오래 걸리는 지연 시간을 의미한다. 일반적으로 대부분의 작업이 비교적 빠르게 처리되는 반면, 소수의 작업이 예외적으로 오랜 시간이 걸리는 경우를 말한다.
예를 들어, 인터넷 검색 엔진에서 사용자가 검색어를 입력하고 결과를 얻기까지 대기하는 시간이 대부분 매우 짧은 반면, 소수의 검색어나 검색 결과는 오래 걸리는 경우가 있다. 이러한 경우 소소의 검색어나 검색 결과가 long-tail latency에 해당된다. 이러한 long-tail latency를 관리하는 것은 중요한 문제이고, 사용자 경험과 서비스 품질에 큰 영향을 미친다.
#
# Write Back과 Write Through
"Write Back"은 캐시 메모리에서 변경된 데이터를 주 기억 장치에 동기화하는 방법 중 하나이다. 이 과정에서, 변경된 데이터가 캐시 메모리에만 존재하는 것이 아니라 주 기억 장치에도 업데이트되기 때문에 데이터 일관성이 유지된다. 이와 반대로 "Write Through"는 데이터가 캐시에 쓰여지는 즉시 주 기억 장치에도 동시에 쓰여지는 방법이다.
#
# write-free constraint
"write-free constraint"는 더 이상 쓰기 요청이 없을 때만 DTWIN 기간 동안 예측 가능한 지연 시간을 보장할 수 있다는 의미이다. 즉, DTWIN 기간 중에는 쓰기 요청이 없어야만 일관된 지연 시간을 유지할 수 있다. 이는 DTWIN 기간 동안 SSD의 내부 작업을 제거하여 지연 시간을 일관되게 유지하면서도, 클라이언트에서 온 온라인 쓰기 요청이 유발하는 대기 시간을 완전히 제거할 수는 없기 때문이다.
#
# bandwidth(대역폭)
computer storage에서 bandwidth는 system과 storage device 사이에서 단위 시간당 전송될 수 있는 데이터의 양을 말한다. 높은 bandwidth는 주어진 시간 내에 더 많은 데이터를 전송할 수 있으므로 더 빠른 읽기 및 쓰기 작업을 가능하게 한다. 지정된 액세스 패턴으로 버퍼링된 쓰기 작업을 storage backend에 주기적으로 flush하면 bandwidth를 높일 수 있어 storage로 더 빠른 write operation이 가능하다.
#
# Granularity
Granularity는 측정이나 분할이 이루어지는 세부 수준이나 해상도를 나타내는 것을 의미한다. flash memory에서 asymmetric I/O granularity는 한 번에 쓰거나 읽을 수 있는 데이터 크기가 지울 수 있는 데이터 크기와 다를 수 있다는 것을 의미한다. Erase-before-write는 새 데이터를 쓰기 전에 flash memory cell을 지워야 한다는 것을 의미하며, erase 작업은 개별 cell이 아니라 cell block에서 수행해야 한다. flash memory에서 erase operation의 granularity는 write or read operation의 granularity보다 큰 경우가 많다.
#
# Soft latency determinism
연속적인 또는 엄격한 latency 결정을 지원하지 않는 일종의 느슨한 latency 결정을 의미한다. 즉, PLM은 SSD의 동작을 잘 예측하고 지연시간을 예측 가능한 범위 내에서 유지하려는 노력을 하지만, 지연시간 결정을 완전히 보장하지는 않는다는 의미이다.
#
# query
본문에서 query는 SSD의 상태 정보와 관련된 데이터를 요청하는 것을 의미한다. 예를 들어, 특정 시간 동안의 error 정보나 성능 데이터와 같은 것들을 요청할 수 있다.
#
# parity bits
" parity bit "는 데이터 블록의 오류를 감지하고 복구하는 데 사용되는 비트로, 데이터 블록에 추가된다. 일반적으로 RAID 시스템과 같은 데이터 보호 체계에서 사용된다. 여기서는 Vigil-KV에서 NDWIN에 데이터를 기록할 때 생성되는 parity bits를 의미한다.
#
# Rollback
rollback은 어떤 작업을 실행하는 도중, 예상치 목한 문제가 발생하여 해당 작업을 중단하고 이전 상태로 되돌리는 것을 말한다. 이는 database, software update, file system 등 다양한 분야에서 사용된다. roolback을 통해 이전에 저장되어 있던 data나 상태로 되돌려서 예기치 않은 문제가 발생하는 것을 방지하고 data integrity를 유지할 수 있다.
#
# Encode
" Encode "는 정보나 데이터를 특정한 형식으로 변환하는 것을 의미한다. 예를 들어, 데이터를 암호화하거나 압축하는 과정에서 데이터를 인코딩할 수 잇다. Vigil-KV에서 parity bits를 encoding한다는 것은 해당 데이터를 특정한 형식으로 변환하여 저장한다는 의미이다.
#
# Chunk
" chunk "는 데이터를 작은 조각으로 나누어서 처리하는 것을 말한다.
#
# stripe
" stripe "는 데이터를 여러 개의 디스크나 노드에 나누어서 저장하는 것을 말한다. Vigil-KV에서는 SSTFile을 여러 개의 chunk로 나누고, 이를 여러 개의 kv-set에 stripe하여 NDWIN에서 처리하고 있다.
#
# identifier
" identifier "는 식별자라는 뜻으로, 여기서는 host에서 각각의 physical function을 구별하기 위해 사용되는 고유한 식별자를 의미한다. 예를 들어, Table 1에서 NVM Set ID는 host에서 각각의 physical function을 식별하기 위해 사용되는 식별자 identifier이다.
#
# instantiate
" instantiate "는 object-oriented programming에서 class로부터 객체를 생성하는 것을 의미한다. 여기서는 "flash firmware"를 per core 즉, 각 코어마다 별도로 생성하여, 서로간의 성능이 서로 간섭받지 않도록 하는 것을 의미한다.
#
저널링, wal (write-ahead log), metadata,
SSD가 성능 최적화를 위해 flash memory에 기록할 데이터를 내부 DRAM 이렇게 나오는 데 여기서 이 세곳의 관계 위치 뭘뜻하는지 찾아보자 (참고10 참고)
lsm kv의 software stack computaion이 storage가 실행하는것이랑 뭐가다른지 알아보기
